工具出更易用的版本了!
【PDF批量添加目录】分级可跳转 - 方法、技巧、工作流 - MarginNote 中文社区
【背景】
最近在准备考研,一些学习资料因为是扫描版,且章节繁多,就算可以ocr自己再手动添加目录但是仍然繁琐耗时。正好在学习python,同时做一些自己的工具,于是就利用pymupdf,pypdf2,cnocr库自己写了一个半自动批量书签生成器。
【参考博客】
使用 python 给 PDF 添加目录书签_Wreng我是002的博客-CSDN博客_python给pdf添加目录
【使用方法】
可以将资料分成两类:
第一类是目录页已经有明确的章节标志,如:
我们把“1.1.1”的 点 看做目录的级别,程序将根据级别将书签分级。
以本书为例:
-
首先将pdf保存为较低版本如Acrobat4.0(以便pdf编辑库的兼容)
-
将文件放入一个新建的文件夹中,文件夹命名为“目录起始页-首页前一页”,比如:这本第10-15页是目录所在页,第16页是逻辑上的第一页,我们将文件放置于‘10-15’文件夹中:

-
点击file导入pdf文件,成功后点击img抽取目录页图片
-
手动编辑目录页图片剔除不必要的信息,并确保目录页目录为单列有序(如果本身为双列目录如本例,需要将两列按照顺序命名并分开保存),编辑方式可为Windows自带的图片编辑方式或者ps等。如果有半透明水印一定要去掉,可以用ps阈值工具,总之图片越干净越好。
编辑前:
编辑后: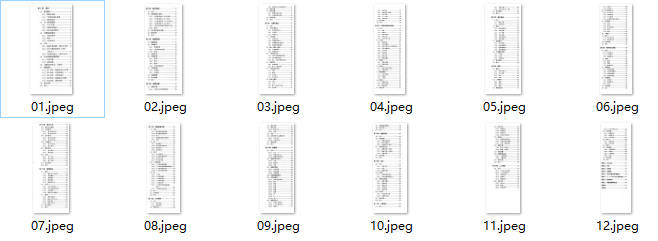
-
点击OCR文字识别,按钮下方显示识别进度

经过一段时间的运算(离线识别库,不需要联网),ocr识别结果会传入下方文本框内:
-
识别结果已经很准确了,经过一些手工纠错编辑,就可以直接生成目录了。纠错需要注意页数是否正确;是否有把“.” 识别成 ','的情况,一些较类似的错误可以选中右键进行批量替换;保证每一条目录在同一行,并使每行结构统一为:“1.2.3这里是标题…166”的结构。

-
接下来点击split按钮对目录预处理,前面数字代表目录级别,稍微检查一下就可以RUN了,之后会在同目录下建立新的带书签的文件,并自动打开

-
完成啦!
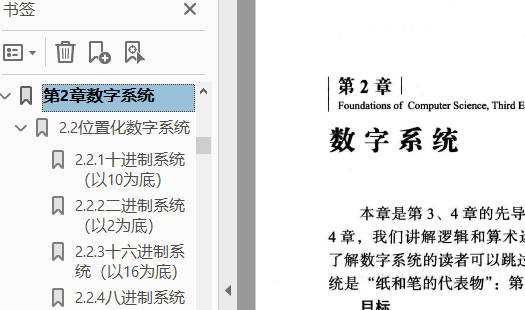

第二类是目录页没有明确的章节标志,如:

那我们只需要手动为目录添加级别,让最终每行目录格式统一为
“3…这里是标题…135”的格式就好,导入到OCR的部分不再赘述。
OCR完成之后:

我们可以选中或者单击某一行,或者多行,点击LEVEL按钮为所对应行添加级数,要注意级数最少为1,最多为9,级数代表了书签的从属关系,编辑后同样单击RUN即可批量生成目录

成功
【问题】
尽管我写出来了但是不太会打包成可执行文件exe。。。只能在pycharm虚拟环境里运行,同时工具的逻辑没有仔细推敲,使用体验其实会差一些,ui也丑,不过好在不需要自己一条一条录书签了。
不知道有没有学计算机的同学会对python项目打包的,可以指点一下我。。有偿请教(试过pyinstaller 以及nuitka,但是因为目前自己才疏学浅对于库的依赖关系还有编译知识有所欠缺总是会出各种问题),所以目前分享不了除非大家电脑都装了python和相关的库,估计过段时间我把打包的问题搞明白了就可以分享给大家了,如果有需要帮忙加目录的也可以把文件发到我的邮箱 vacuumarea@qq.com~
【更新】
打包问题解决了,就是文件有点大,而且操作逻辑并不直观。最近打算配合正则表达式重新写一下软件的逻辑。