PDF批量建立多级可跳转书签(目录)2.0
背景介绍
最近在学习python,因为很多时候找到的pdf 资源没有可跳转目录,文件导入Marginnote3或者其他笔记软件之后很难根据索引跳转到自己想要的部分,于是前段时间利用Cnocr以及Pypdf2库写了一个[半自动的目录工具](https://bbs.marginnote.com.cn/t/topic/32389),可是实际上那个工具使用逻辑并不符合一个正常用户的行为习惯,且pypdf库很久没有人维护了总是会出一些问题。所以还没学会打包文件项目就流产了。于是我又用Pymupdf重新写了一个更加易用的版本,可自动通过目录特征确定目录从属关系(之后解释),并且还有页数错误自动检测等功能。
不论目录有多少一般情况下整个过程不会超过10分钟。
我称之为 PDG_v1.2.0(Pdf Directory Generator)
使用方法
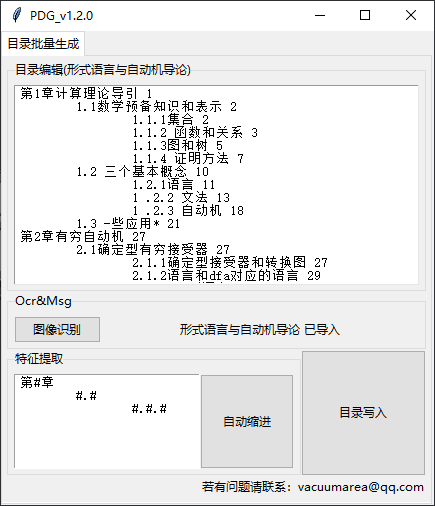
基本界面
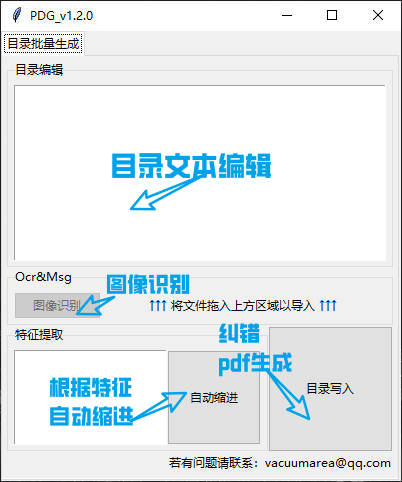
忽略UI设计哈。。。能用就行了没时间做了
编辑流程 :
按照格式建立文件夹 → 导入pdf → 目录图像调整并识别文字 → 文本粗编 → 特征提取自动缩进 → 目录写入,根据提示修改错误 → 生成PDF。
详细介绍
-
建立文件夹
文件夹命名格式:‘目录起始-首页前页’
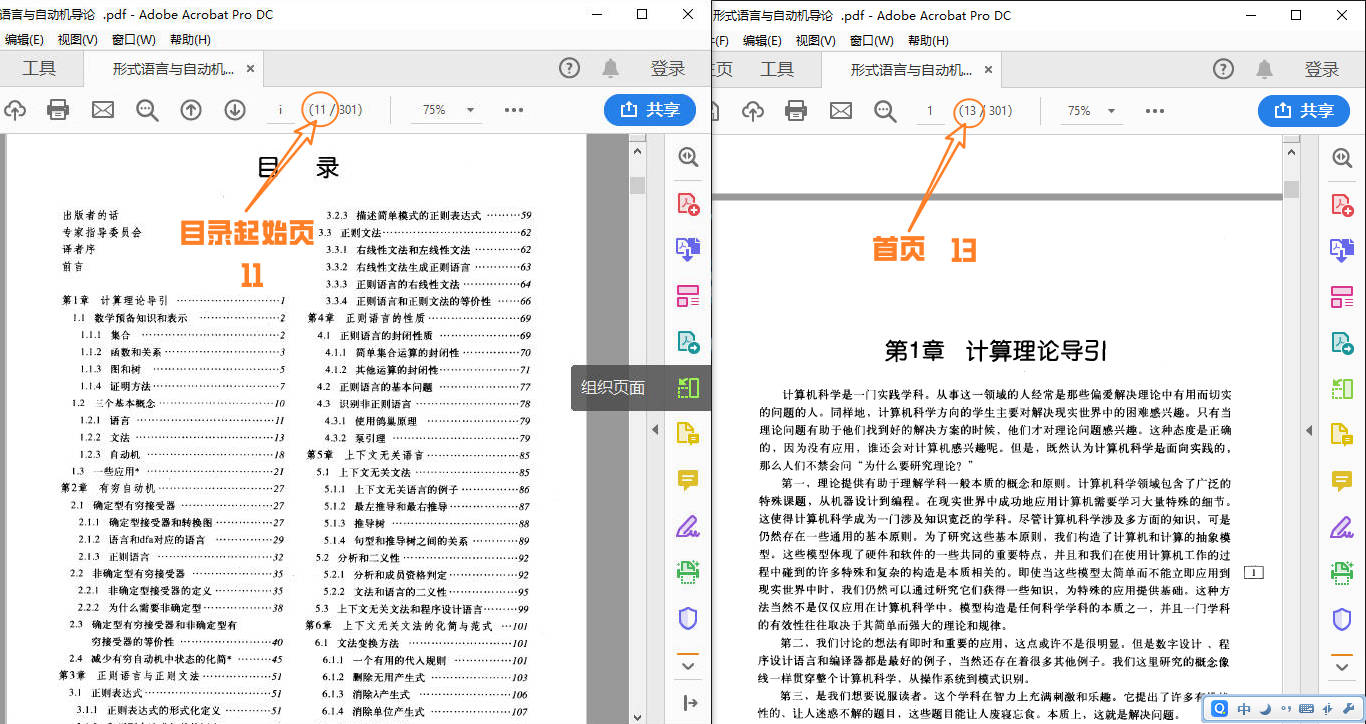
以 《形式语言与自动机导论》 为例,目录起始页是11,首页是13,首页前一页(在这里就是目录最后一页)是12,所以创建文件夹‘11-12’,将pdf放入文件夹
-
目录图像调整并识别文字
打开PDG工具,将文件夹里的pdf文件拖入文本编辑框,之后会自动弹出导出的目录页图片,imgs文件夹存储提取的目录页图像,需要手动编辑图片方便后续识别,
最终图片需要保证单列,有序
处理前:
处理后:通常不需要怎么处理,图片越干净越好,不要有水印、严重歪斜等情况
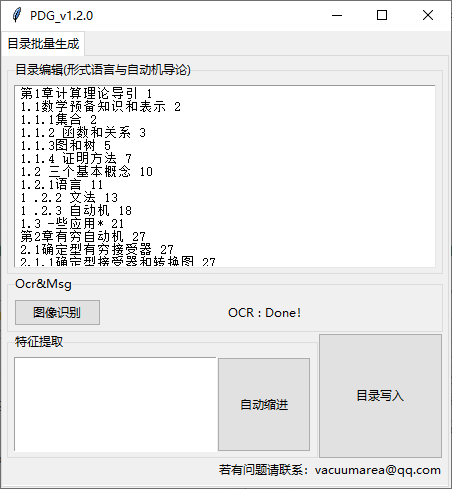
之后点击 图像识别 等待 ocr识别
-
文本粗编 + 特征提取自动缩进
Cnocr识别结果还是很不错的,这里就不需要再额外编辑了,在文本编辑区域右键提供了常用的文本编辑命令比如: 剪切,复制,粘贴;另外还提供了全文替换功能。
这个工具使用Tab键,即制表符,来表示目录从属关系,比如:
’'
第1章计算理论导引 1
1.1数学预备知识和表示 2
1.1.1集合 2
1.1.2 函数和关系 3
1.1.3图和树 5
1.1.4 证明方法 7
1.2 三个基本概念 10
1.2.1语言 11
1 .2.2 文法 13
1 .2.3 自动机 18
’'
因为书本目录往往具有很明显的结构,所以我们可以使用特征提取工具告诉计算机目录的缩进结构。使用方法很简单,只需要按照目录关系,在下方特征提取文本框里,在应特征文本行前插入相应数量的制表符(Tab)即可。
特征文本格式:“第一章”->“第#章” “4.5.3”->"#.#.#",没有需要替换的就不用修改了
以本书为例,仅需在下方文本框输入:
’’
第#章
#.#
#.#.#
’'
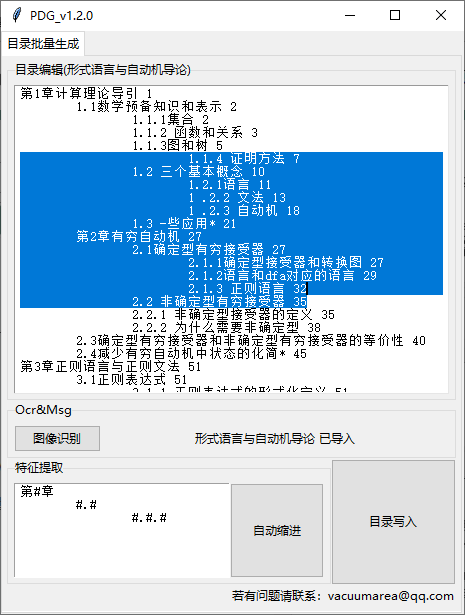
点击自动缩进:
当然,对于目录没有明显结构特征的书籍,我也提供了批量缩进的功能:
选中多行,Tab批量缩进,Shift+Tab批量回退
-
目录写入,根据提示修改错误,生成PDF
.
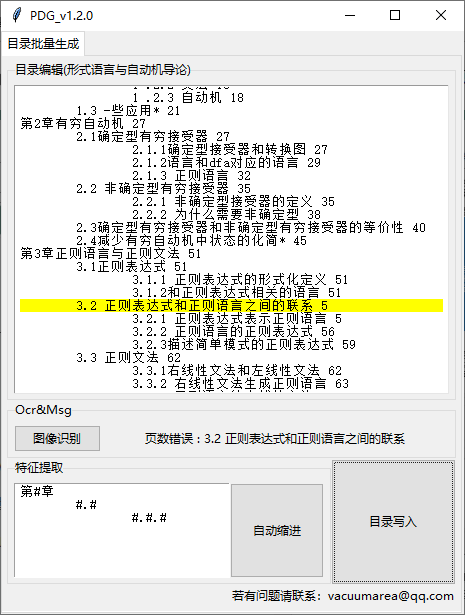
我们就可以点击目录写入生成pdf了
如果目录有问题,程序会自动找到并提示出错条目,错误类型比如:页数不符合逻辑(OCR识别错误),缺少页数,缩进错误等。怎么理解缩进错误呢?比如一级目录下紧跟着三级目录,这就好比老爷爷没有儿子但是凭空多出一个孙子。。。啊不重要反正都会提示的。
修改好这个错误之后重新点击目录写入,会提示下一个错误,直到最终pdf生成。程序会将带目录的文件保存在同一文件夹下,并且在‘toc.txt’文件存储本书的目录。
此时我们就大功告成啦!!!


下载链接
百度网盘:
链接:百度网盘 请输入提取码
提取码:6666
我只是入门,OCR库使用了numpy,torch等包,无论怎么打包最终文件都特别大。。。我尽力了。。只支持win10以上,不支持macos
打算以后有一些扩展功能可以加进去,不过目前还没啥想法。如果有使用上的问题或者建议或者bug都可以发我邮箱 vacuumarea@qq.com 与我沟通 ~
有时间我整理下代码,到时候传到gitee或者github上,这样只需要安装python和一些必须的库就都能运行了,不用再下载那么大的打包文件了。目前只在我舍友的电脑上测试过,希望能派上用场。