在网课使用MN3的OCR功能能期间,遇到了这样几个问题,使得使用体验不是那么舒适。
1、在识别过程中会出现一行或几行文字识别不上的情况,只能用套索手动节选,大大影响效率(识别的上和识别不上的文字是同一样式同一背景)
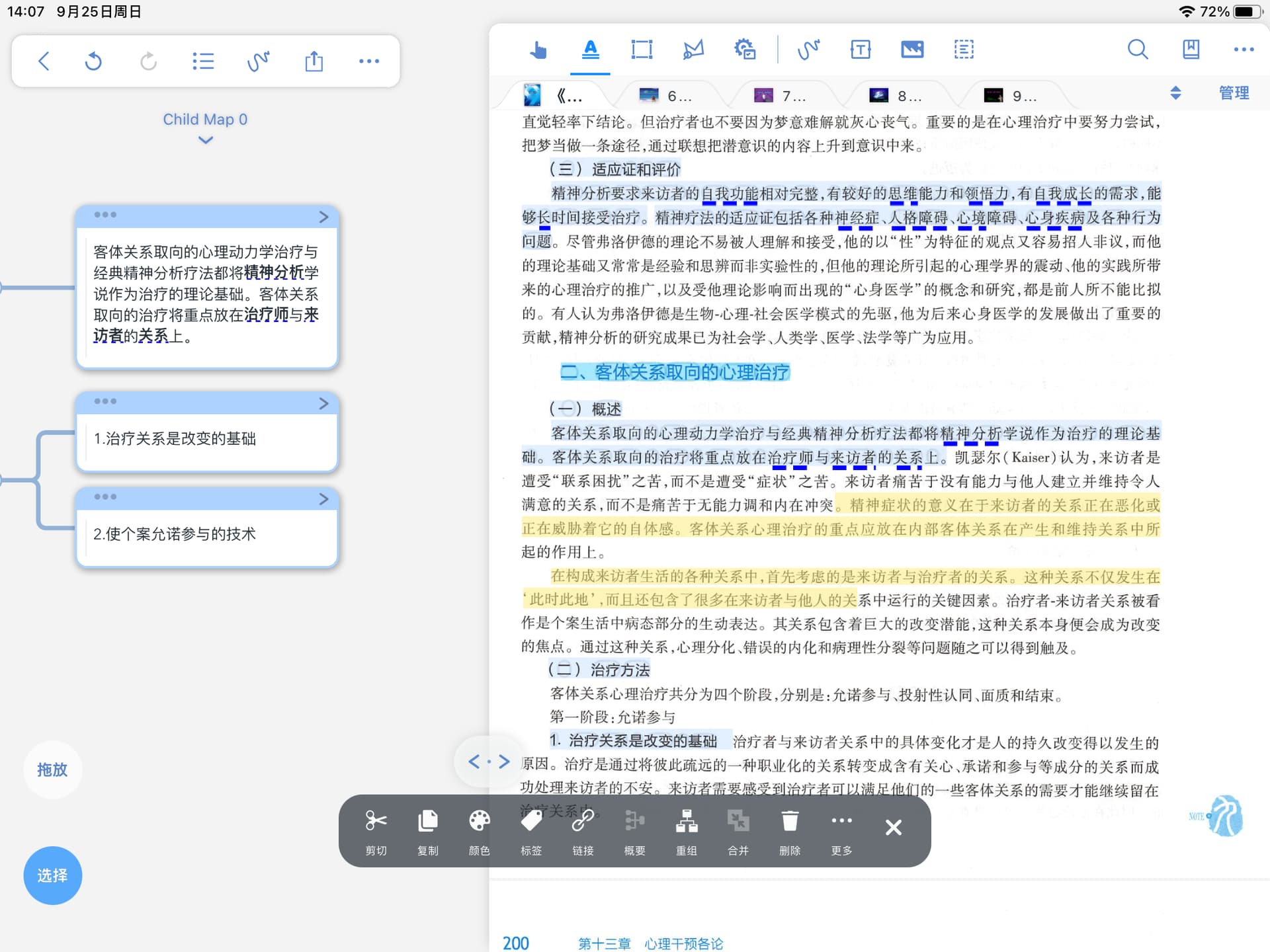
注:图片中能正常摘取的部分显示黄色,中间有一小行(“起的作用上”)无法被正常摘取
2、在识别出来的文字中,有些有下标和希腊字母符号的地方无法被识别摘取,通常会被错误地识别为逗号,只能在卡片里手动订正。
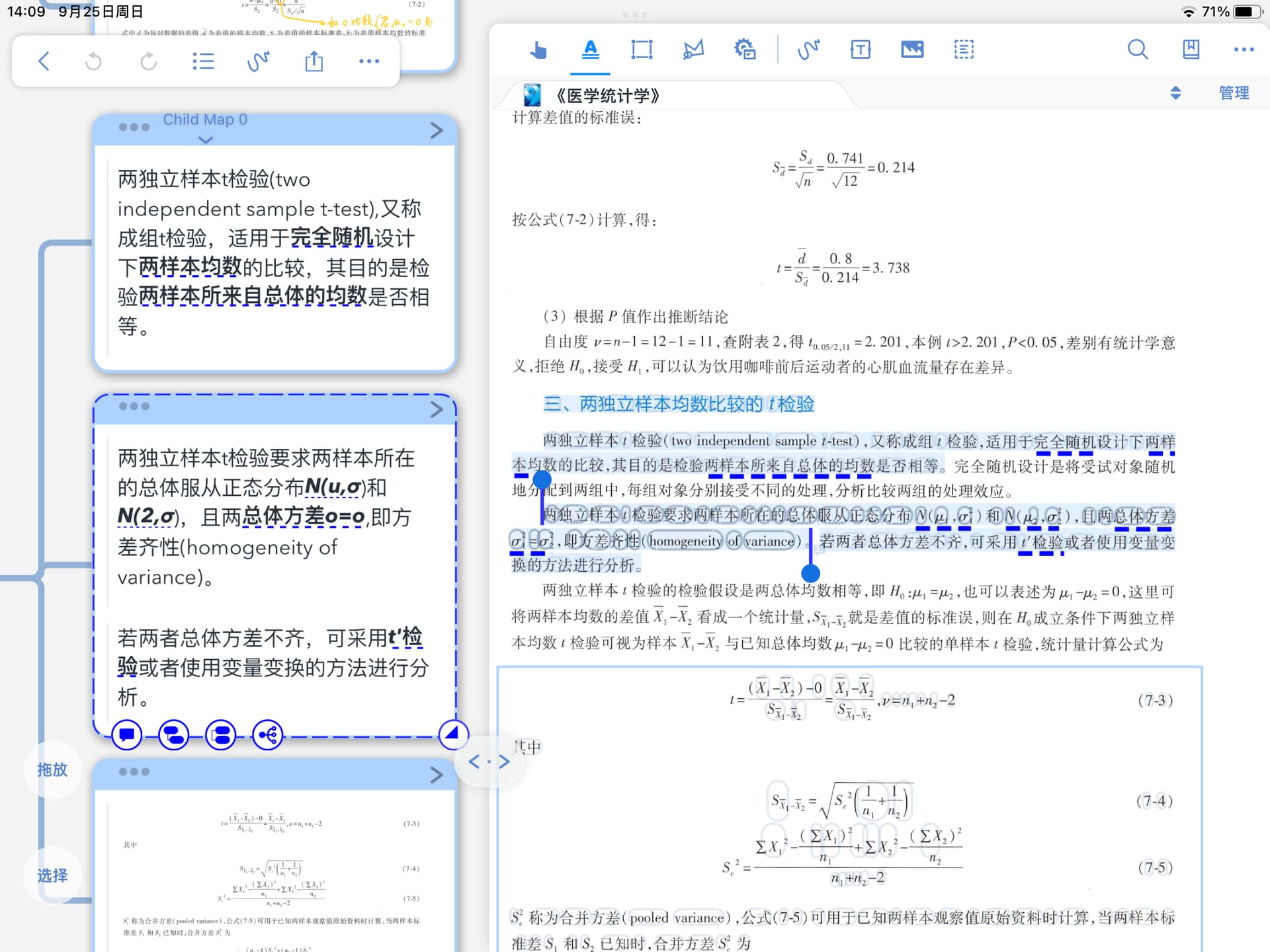
如图中OCR经过在线校正后还是有明显错误
3、在跨页摘取的时候,页眉和页脚也会被一起摘录,不知可否排除此干扰
4、在有插图的文件中,一段话的文字摘录会带上图片里不需要的文字,也很影响使用体验。
目前想到的是这些问题,不知是否有解决方法,或者是相关技术人员能对此进行改进。我想如果以上问题能够被解决的话,MN3将成为在网课时代一个极强的学习利器。