问题描述
和ipad的ios系统的marginnote不一样,由于macos上没有对整个pdf进行ocr的功能,因此对于扫描的 图片pdf 非常不友好,不能选择文本,只能用框摘录.而像划重点,标题链接,全书搜索这样的功能更是完全无法完成,因此引发了若干人血书.
其他有同样需求和心得的帖子有:
官方相关表态有
https://bbs.marginnote.com.cn/t/topic/2821/6?u=tianyilt
因此,在等到新版本解决之前,特别需要一个方法来将 图片pdf 转化为 ocr后的pdf ,从而在macos上也有和ipad一样的阅读体验.
这个方法有以下要求:
- 能够在转化书籍的同时保留原书的摘要与脑图结构。
- 修改后pdf样子要与原先保持一致,就如同ipad上ocrpro后的pdf一样。
名词约定:
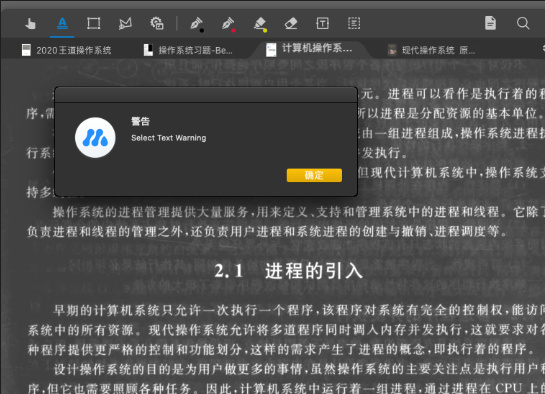
图片pdf:所有文字都不可以选择,每页只是一张图片.如果你强行想要选择文本,就会这样↓
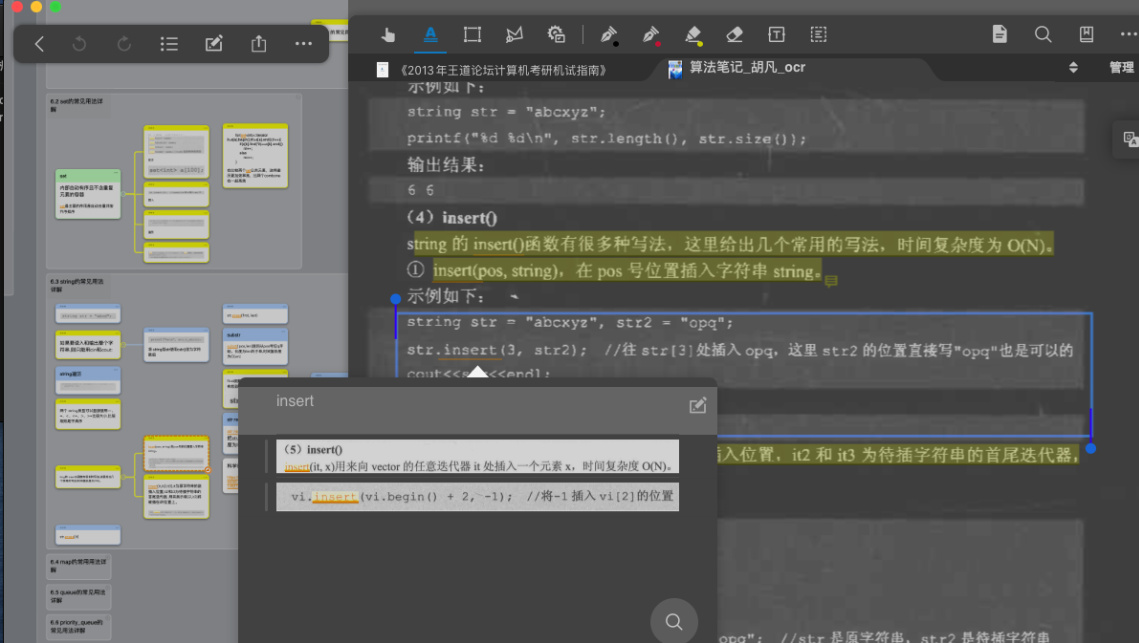
ocr后的pdf:所有文字都可以选择,因而支持划重点,标题链接,全书搜索这样的功能.
环境准备
系统环境:
- macos10.15(目前演示实验环境是运行在vmware中)
- windows10 作为转化pdf的工作环境
涉及软件:
- ABBYY_15.0 用于转化pdf,是ios端ocr的技术提供方,因此只要把pdf经过abbyy处理之后就可以有一致的体验
- FreePic2Pdf 用于将原先的图片pdf的目录导入ocr后的目录结构
操作步骤
步骤千万条 备份第一条
操作不规范 自己两行泪
一切开始之前把相关的脑图包括文档一起备份
abbyy出于教学和科研目的使用方法
实不相瞒,我出于教学和科研目直接通过百度网盘搜索工具找到了相关资源.但是根据社会主义核心价值观,请大家自行查找资源,并建议支持正版
安装完后可以在路径 ABBYY_15.0.112.2130_Green\ABBYY FineReader\ 中找到 FineReaderOCR.exe
界面如下
ABBYY ocr方法
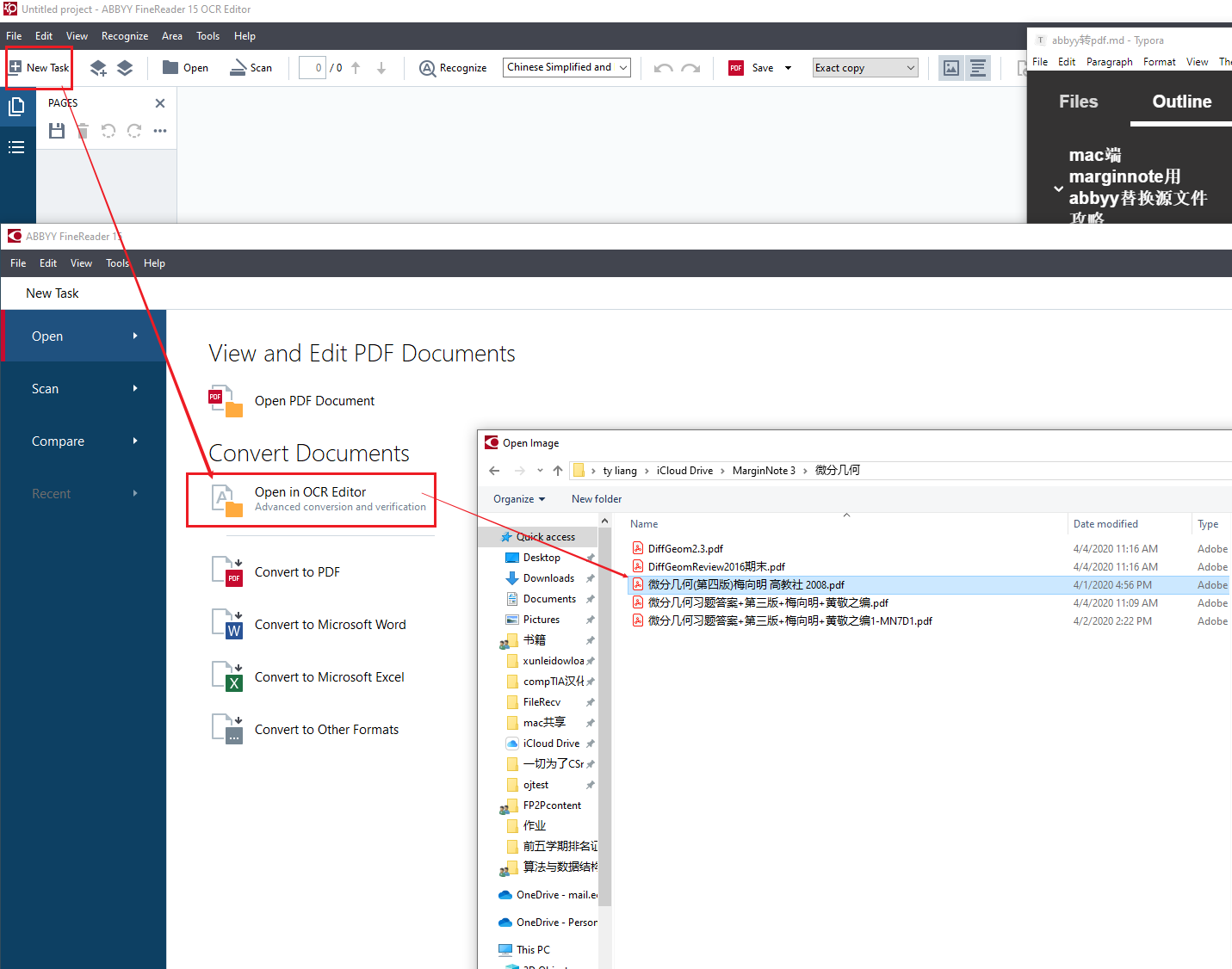
点击file->new task,然后点击Open in OCR Editor之后选择目标pdf
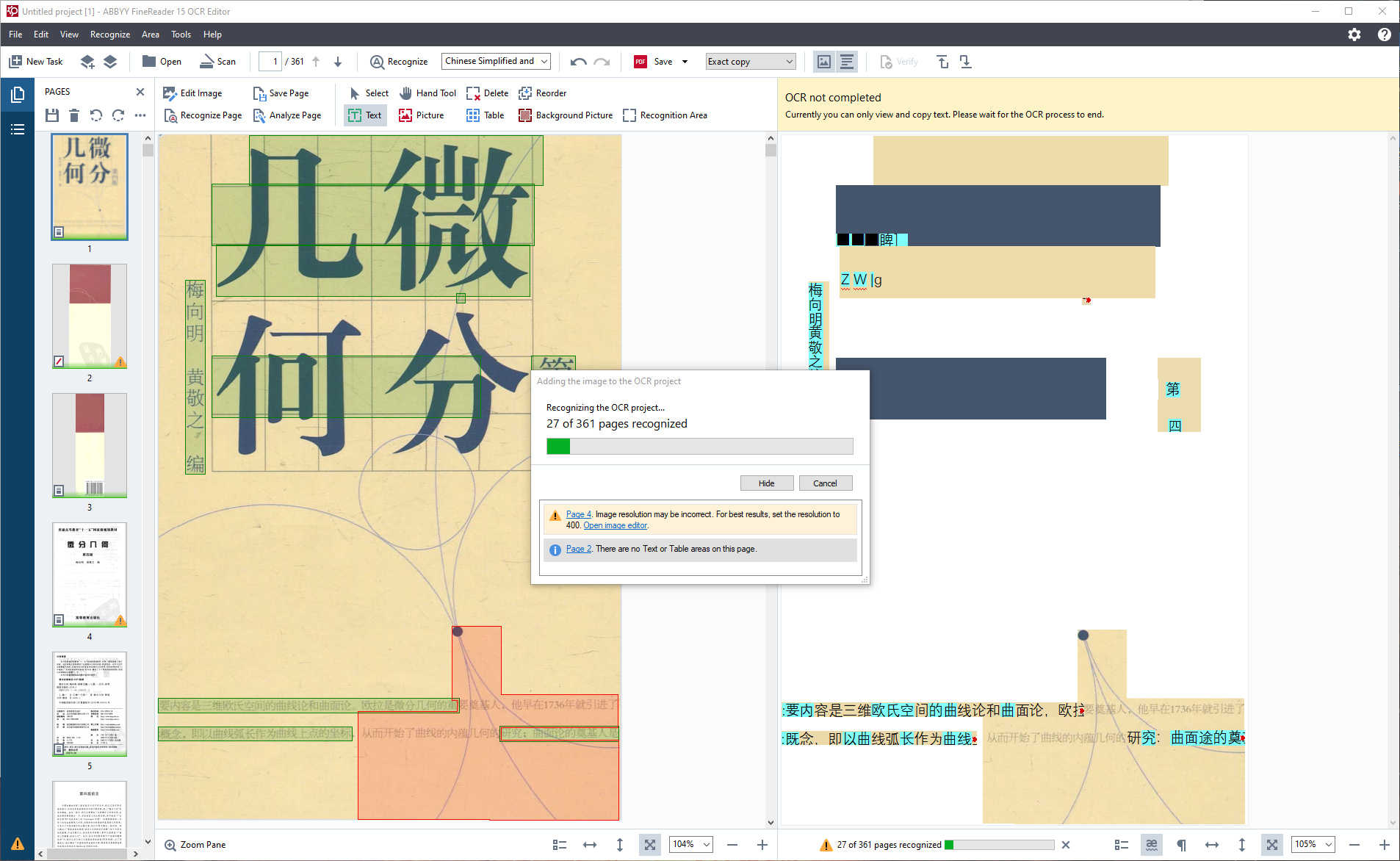
之后就等待他ocr结束
![image-20200507214755485]
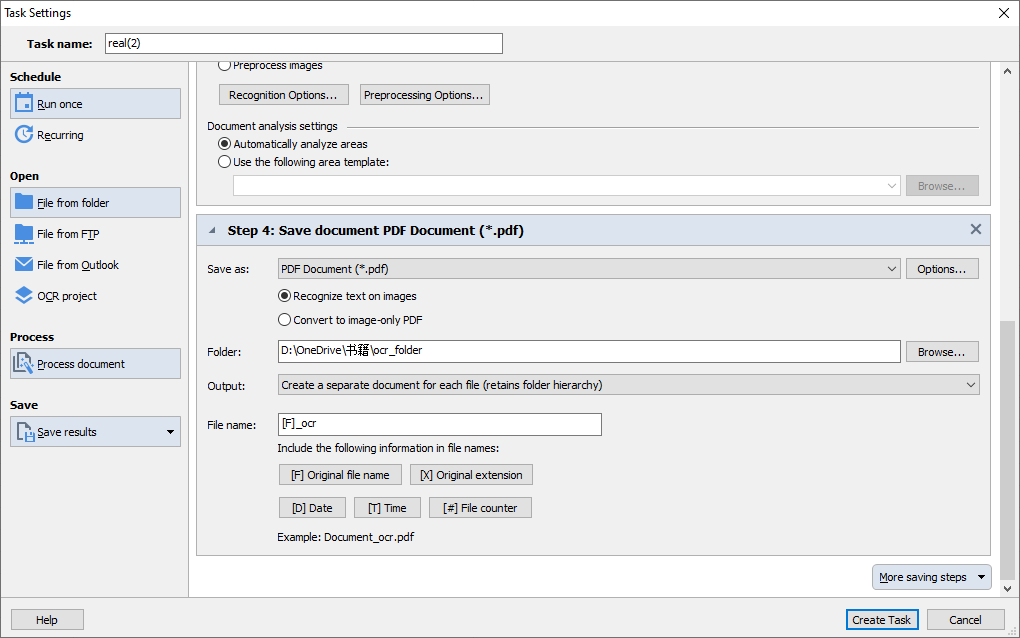
完成之后点击另存为Searchable PDF Document,Searchable PDF Document就是我们想要的ocr后的pdf
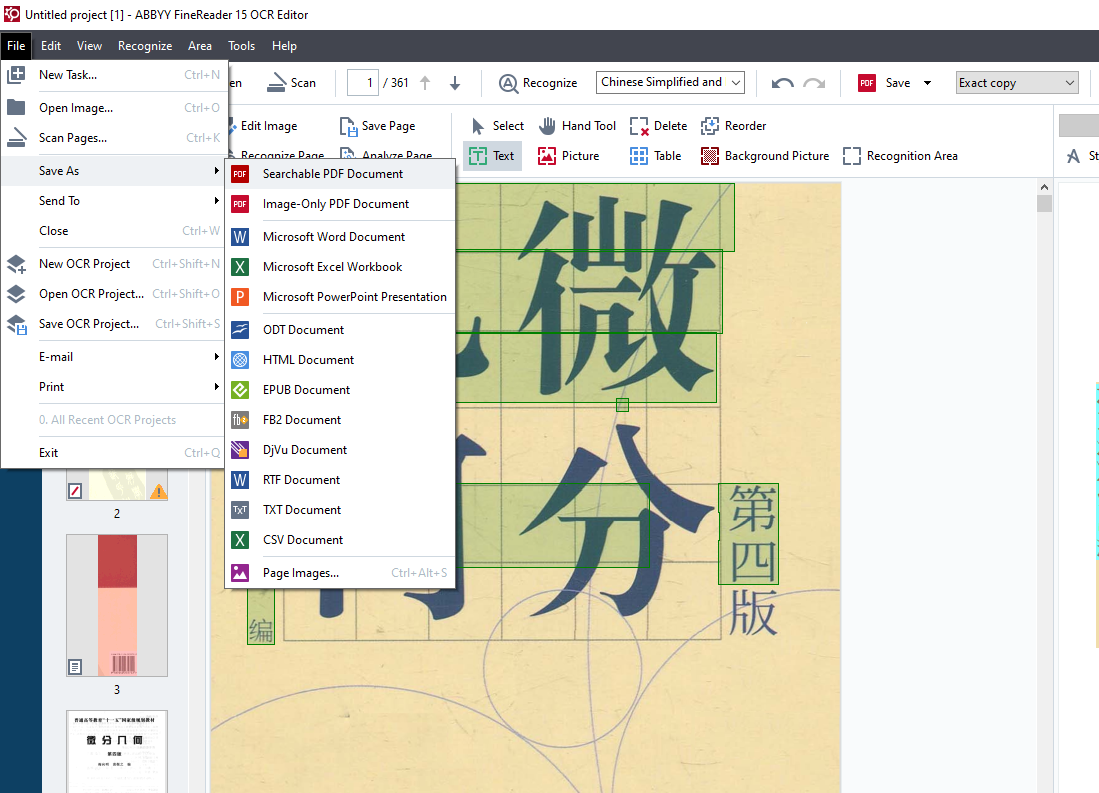
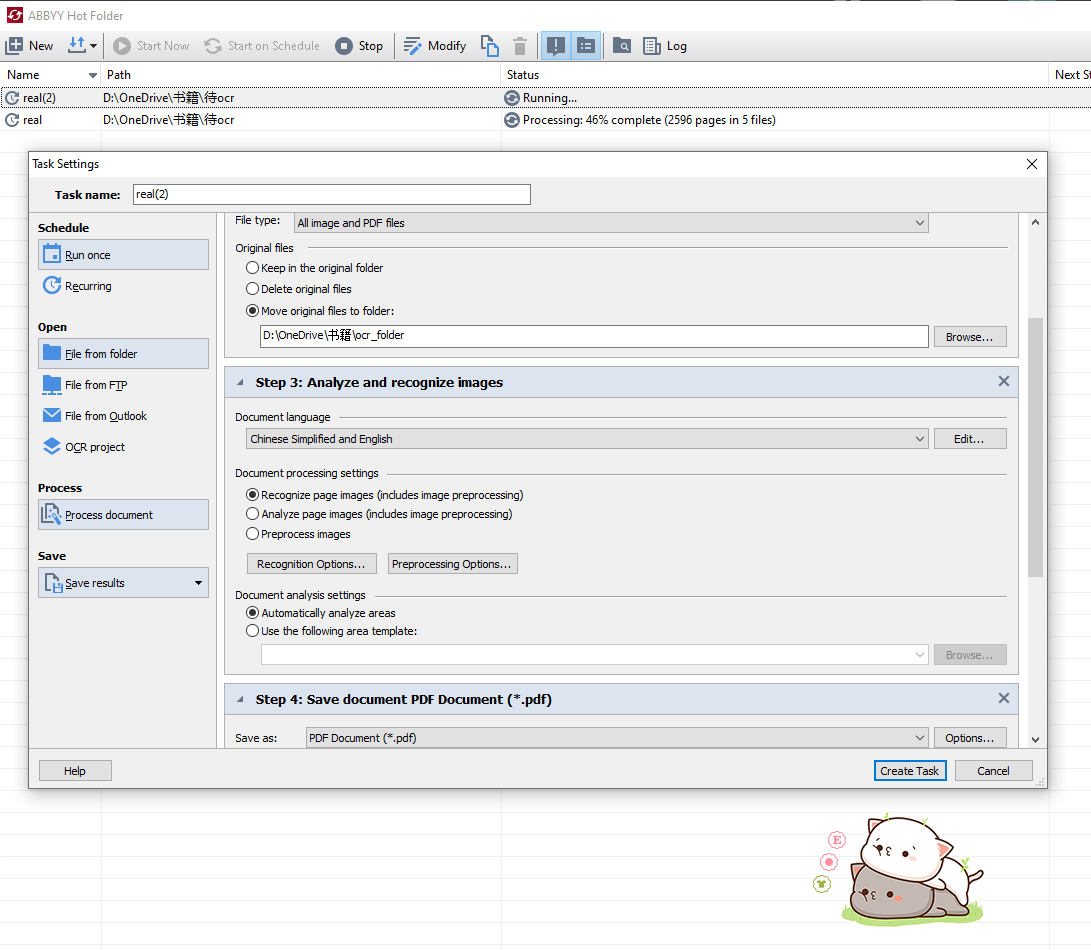
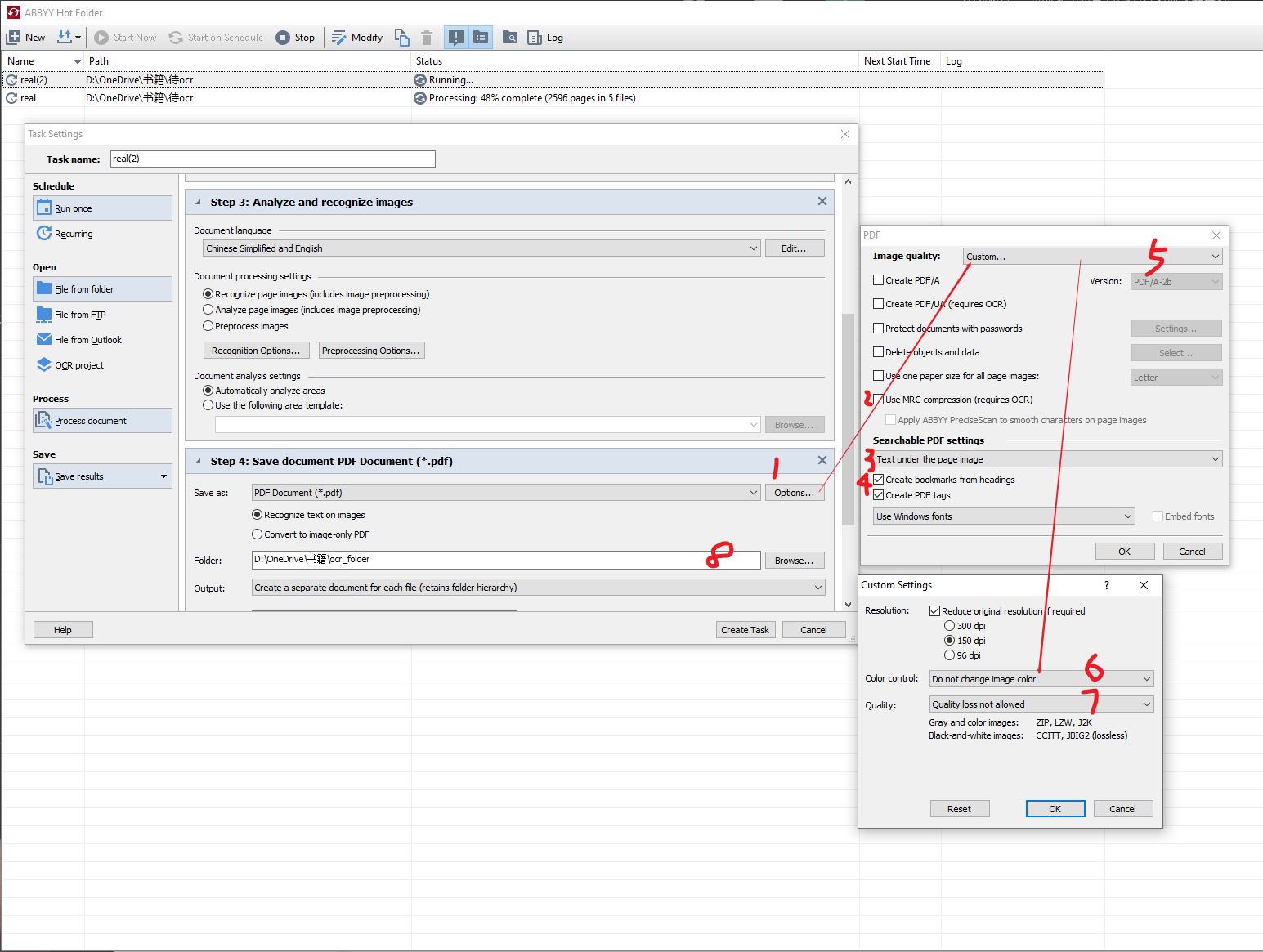
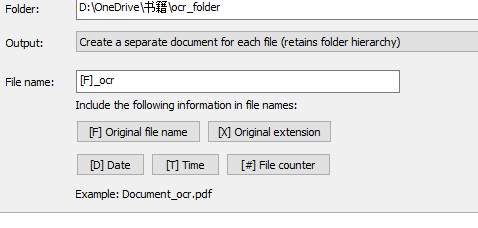
abbyy保存以及相关参数设置
保存的时候可以进行参数设置,这里我
-
在Searchable PDF settings里面选择Text under the page image.这意味我们看到的内容是和原版pdf一模一样的(最上面是图像层) 而我们搜索 摘录选择的文本是在文本层,位于图像层下方.
-
把质量选择为自定义,在里面选择质量不损失
-
use MRC compression 这一个选择整个勾掉 压缩会影响画质
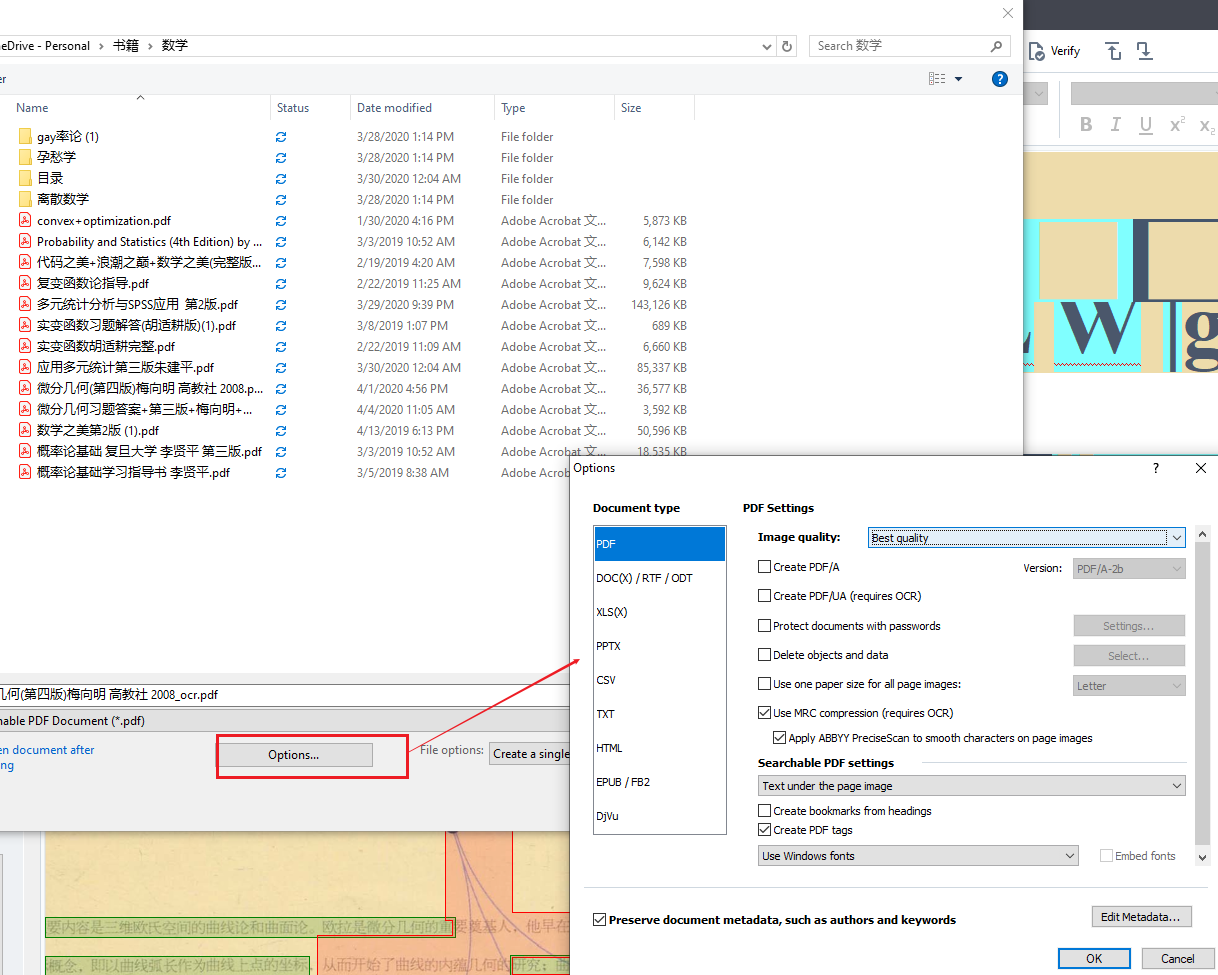
截取自群内大佬的图↓
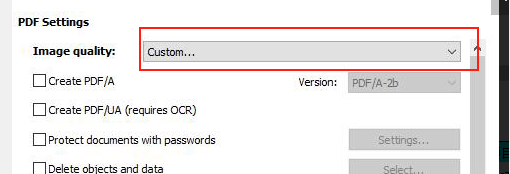
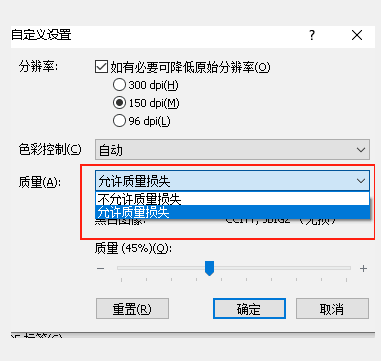
在质量不损失之后就可以有非常清晰的结果
更新:经过探索,其实这里参数可以这样设置,结果会更好
用FreePic2Pdf来保障目录(并演示车祸现场)
目录结构千万不能改变!!!如果转化后的书籍的目录发生了改变,通过重新连接后的笔记会发生如下喜闻乐见的事情
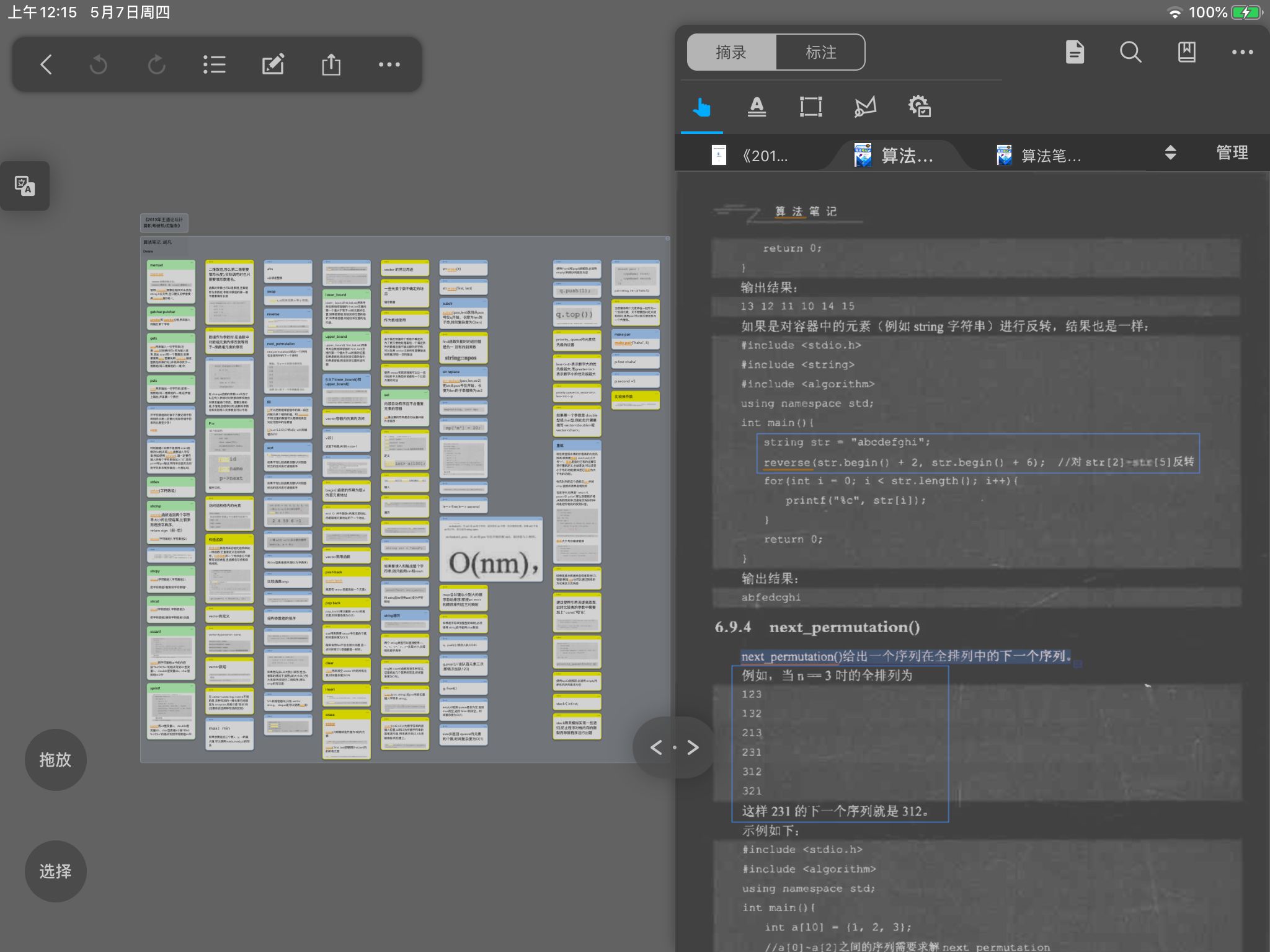
请少侠自己重新拼思维导图吧.原先的目录结构是这样的↓

这件事情发生的原因是当初做笔记摘录的时候选择了自动插入 来使得新卡片在脑图中的父节点就是目录.在文档目录结构改变后,这些脑图卡片的父节点就全部跟着目录一起灰飞烟灭了,因为父节点是由目录来决定的.
来使得新卡片在脑图中的父节点就是目录.在文档目录结构改变后,这些脑图卡片的父节点就全部跟着目录一起灰飞烟灭了,因为父节点是由目录来决定的.
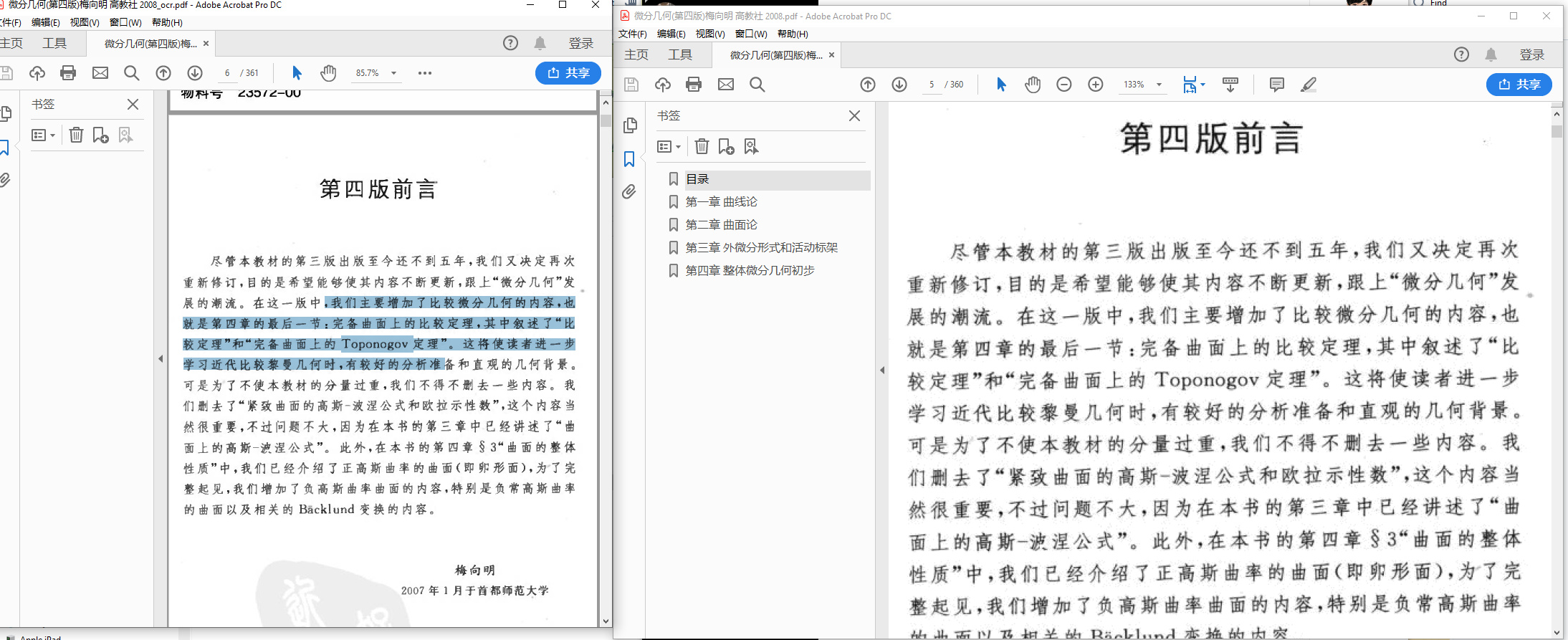
在讲清楚了让转化后的pdf目录和原先一致的必要性之后,现在开始回顾刚刚被ocr好的pdf
我们发现基本字体颜色没有改变,能够选择文本.但是没有目录.
我们在开始一切操作之前,先把原版pdf与ocr好的pdf进行备份
我们在开始一切操作之前,先把原版pdf与ocr好的pdf进行备份
我们在开始一切操作之前,先把原版pdf与ocr好的pdf进行备份
三遍完毕,开始进入目录操作:
- 从原来pdf取书签
- 将取出的书签导入到ocr后的pdf
这个时候轮到freepic2pdf出场了,点击右下角更改PDF
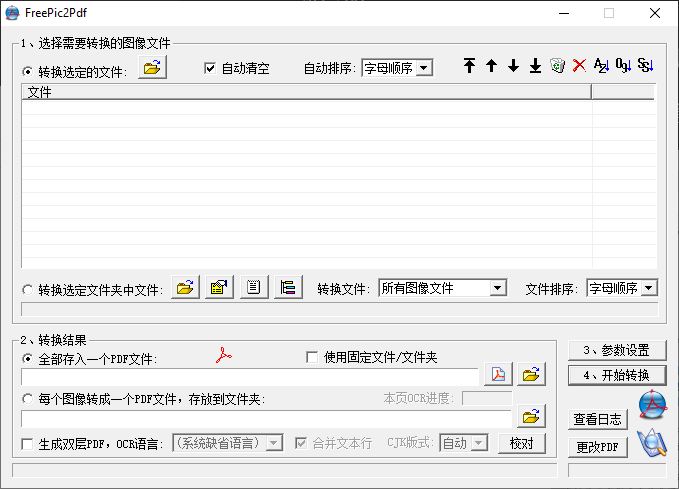
首先点击取书签,选择原版的pdf,存放接口文件的文件夹随意,但是请把路径复制一遍.最后点击开始
点击挂书签,选择ocr后的pdf,填写接口路径,最后开始
如果失败,请关闭所有pdf查看器
最终,打开ocr pdf查看效果,比较圆满
在marginnote删除原来的pdf
先把ocr的pdf放到marginnote相应目录下
之后删除原来的pdf
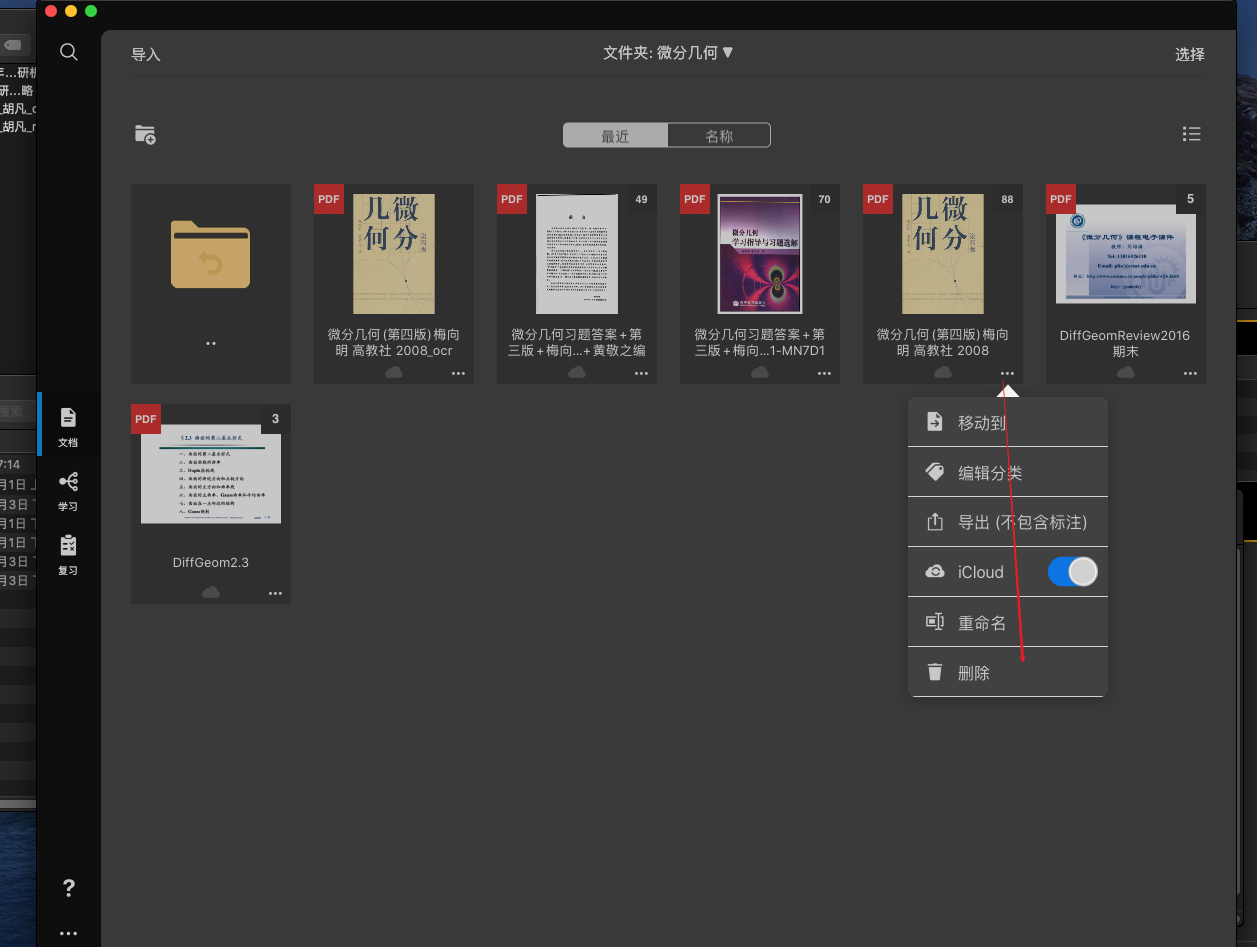
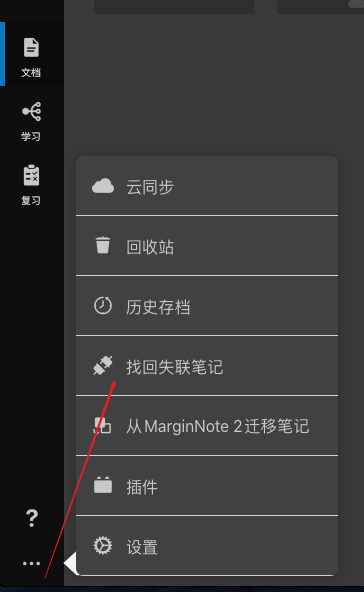
恢复连接选择新的ocr完毕的pdf
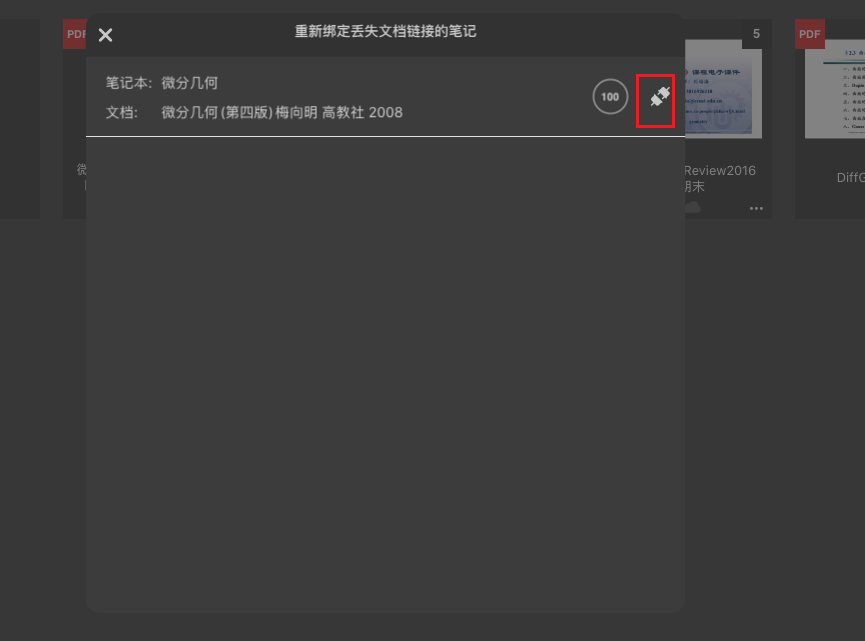
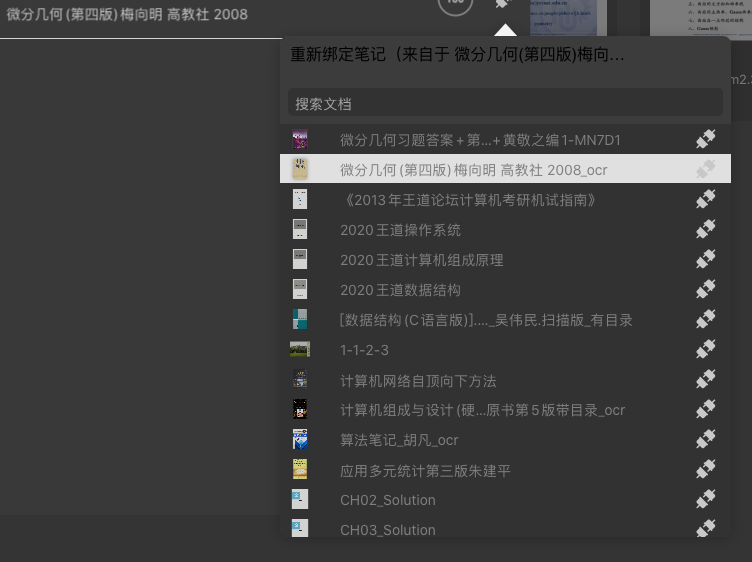
把文档关联了,最终成功
未来展望
目前操作还是有些繁琐,未来希望能将pdf处理流程变得:
- 自动化:封装成一个脚本
- 批量化:能对多个pdf同时运行
- 目前这个操作是在windows上完成的,需要探索一条在mac上编辑的路径
希望官方能够在ipad端的使用abbyy进行pdf ocr之后,在icloud上建立一个ocr后的pdf副本来供mac端使用
此外freepic2pdf的给pdf批量添加目录也是很方便的事情,大致工作流如下:
- 导出pdf目录
- 在淘宝或京东商品目录找到书籍目录
- 用几个常用正则表达式对目录文本进行批量替换修改,使得目录文本满足freepic2pdf的目录语法
- 导入目录
具体操作最近会总结分享的